


MP3 sounds nasty somehow, esp. with fricative sounds, unless using highest bit rates, and ogg sounds fine with 96kb/s nominal for stuff like this. I can't explain it, but when listening with headphones or in the car, mp3 gives me some sort of "ear fatigue" (it gets unpleasant, I need to stop) rather quickly, not so with ogg.
"The synth" is something I cobbled together in my high level language platform of choice, C# / .NET.
And I was even too lazy to implement a dump-to-disk feature as I saw that Audacity can record that via some loopback feature. It's basically a bunch of 2nd order SVFs with output level controls, oscillator & noise source, envelope gen, and lots of GUI knobs for everything to play with.
Let's Design and Build a (mostly) Digital Theremin!
Posted: 1/1/2018 3:21:34 AM
Posted: 1/1/2018 9:58:27 PM

tinkeringdude, I'm guessing your synth code is float-based?
===========
In between the revelries and general merrymaking I'm made some headway, but I don't know where it's taking me! Got a double-damped SV filter going today, where each integrator has its own damping negative feedback. Feeding it with a sine wave and giving it extra damping on the LPF output negative excursions, I'm seeing exactly what the Excel sim shows. I made the damping threshold variable but zero works best (you don't want to hear a sine wave before the glottaling action kicks in). Adjusting the damping ratios for maximum effect sounds good, but only maybe a little better than my previous squaring waveshaping. And it aliases more. Can also adjust the center frequency of the filter relative to the oscillator feeding it. Higher ratios do give a more "open" sound, but really it sounds much like a mild LPF being opened up. So all these papers are teasing out the mathematical nuances of something that doesn't seem like all that big of a deal. Chasing after specific waveshapes to give specific harmonics feels kind of like a suckers game, as there isn't a one-to-one correspondence, but rather many waveshapes to one set of harmonics. On a deeper level, waveshapes which have baked-in spectral coloration that makes certain notes or registers more realistic are likely to negatively impact the realism elsewhere.
===========
I've mentioned Google's wavenet before (link) but I want to again because it is so freaking eerie - eerie that a neural network can do all that just predicting the next PCM sample (kind of a Linear Predictive Coding from hell), and eerily human sounding both when speaking and when spouting gibberish. Vocal simulation has this big initial payoff with very little effort (a buzzer and three filters give you a realistic singing voice) but articulation details constantly toss you back into the uncanny valley - it's a very diminishing returns kind of thing. Bludgeoning the entire problem at the most basic level with a neural net is pure genius, and it works so remarkably well I almost don't believe it.
Posted: 1/2/2018 12:40:48 AM
Yes, it's all float. I made an integer port of most parts years ago, but that sat to rot while I was continuing on the PC fixing problems and actually doing things with the components. There was some slight noise problem IIRC that I hadn't looked into. Haven't ported that particular filter (from the recording) to integer, though. I should hope it works on some $3,- 32bit MCU, the formula came out of a 1980's book (Chamberlin). I guess resonance can be a problem with regards to error? Most of my fixed point programming had to do with computer graphics in the late 1990's, stuff might have looked somewhat ugly sometimes, but nothing usually exploded in your face, or ears, unless it was intentional :-)
---
but rather many waveshapes to one set of harmonics
Hehe! I noticed that with surprize when I wasn't aware that our ears apparently don't give a damn about phase relations of harmonics. "Hey, that looks almost like a sine, why does it sound square?" Because it was a very "rounded out" waveform. Then I started to plot waveforms, deliberately changing just the phase offsets of harmonics to get a feel for how different they can look.
EDIT:
On a deeper level, waveshapes which have baked-in spectral coloration that makes certain notes or registers more realistic are likely to negatively impact the realism elsewhere
I did think about, several times, why stick to the source + filters scheme. Why not just look at spectra and how a spoken word morphs between those, and try to emulate that by whatever means gets that job done.
From the limited knowledge I have of such things, it just continues to seem like there's no option nearly as computationally cheap as that source + filter model to accomplish that, so that's why I stuck with it so far. (it is supposed to run on some MCU at some point, after all. Although I won't ignore byproducts of this exploration which may be better suited to other host platforms)
---
That WaveNet thing is interesting. So far it was more on the "no no" side in my head, having neural networks touch individual samples, thinking it must be quite computing intensive. That notion is either wrong, or the google thing runs only on a PC or something as powerful.
It had crossed my mind to use smaller networks to control synth module modulation parameters and such, to aide with speech production on a higher level, perhaps saving some work. I.e. instead of me having to do another "speaker synth patch" in all aspects by hand, just train it to something. My experence with NNs does not go beyond executing some demo code & playing with it, though, I have no idea how small they may actually be for this application & if it could all run on a cheap MCU.
Posted: 1/2/2018 4:03:05 AM
I use a modified Chamberlin SV topology, with integers because floats are too expensive on my lamer platform. I really don't get why Chamberlin himself didn't modify it, his first order filter uses the modification, which is to do the frequency attenuation post integrator rather than pre. The integrators have to be wider to accomodate the gain, but you get plenty of resolution with 32 bits. I've heard there are issues filtering with floats, particularly with limit cycle pumping of low frequency IIR filters. And the floating point pipelines in many processors don't handle denorms directly, trapping to software solutions that can be orders of magnitude slower. Programmers often insert tiny offsets to get around this (I've seen this in PC-based DSP code and it's quite puzzling when first encountered - IIR tends to decay to nothing, generating gobs of denorms as they fall into the black hole of zero).
I'm looking for organic solutions in DSP space, which is kind of contradictory. I think the vocal researchers do too, as natural touchstones tend to let you know you're heading in the right direction, and lend some nature-based gravitas to what you're doing ("hey, I got the waveforms from the voice box itself"). Altering natural parameters can often solve / sidestep a lot of nuance type problems, and the parameters themselves are often more intuitive than those we might think up in an intellectual vacuum. But I suppose one can take it too far. Simple vocal stuff has a lot of low-hanging fruit.
From what little I've read, Wavenet is quite computationally intense, and until recently not possible to do on a PC in real-time. A high-power GPU thing I'm pretty sure, nothing we'll be doing anytime soon on a Raspberry Pi.
=======
What I really want to do is somehow capture the full gamut of breathy to vocal, with a random kind of rattly thing in-between, and to do it as elegantly as possible. I realize now that the breath sound itself is just turbulence in the tract, and not the thing that stimulates the chords to vibrate, though there is some turbulence with the chords vibrating. Gotta look at more mass / spring physical models I suppose, the analog of which can often be boiled down to an SV or three interacting non-linearly. The need for exact pitch might be a problem, though even non-linear VCOs can be linearized via PLL feedback loops.
Posted: 1/2/2018 6:42:34 PM
Sine * Ramp^n
A lot of glottal generators run a phase ramp (raised or unsigned sawtooth) through one or more non-linear functions. I got the idea yesterday to take a standard NCO phase ramp, feed it to the SIN2 subroutine to generate a sinewave (as normal), but then take the phase ramp and square it several times, then multiply it with the raised and normalized sinewave. More squaring of the ramp makes the result lean over more, makes the duty cycle narrower, and increases the speed of the falling edge:
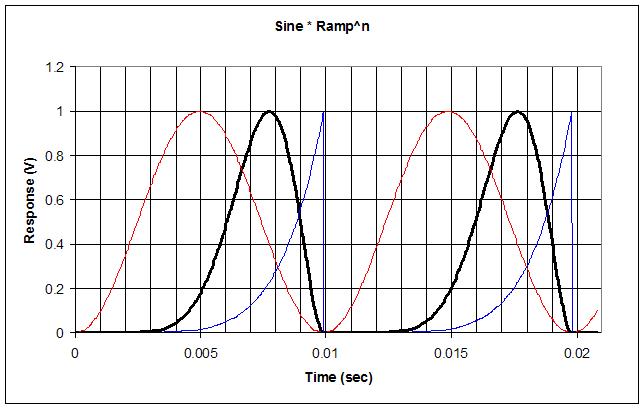
The above is 3 squarings (8th power) in Excel. The thin red trace is the sine wave, the thin blue trace is the multiply squared ramp, and the thick black trace is the result of multiplying them. It sounds pretty good and doesn't alias much. Harmonic amplitudes are nice and even with no dips. I can hear what they mean by "openness" or a thinning of the bass and accentuation of the harmonics when the squaring is increased. And I can also now hear the reason for independent control over the openness and harmonic content, as you might want more harmonics but not have this cut the bass content. I've got it coded so that 0 squarings give a sinewave, and there is a small second order polynomial that normalizes the output amplitude based on the squarings.
It's running on the prototype, but there is an obvious DC balance issue; they were careful to remove this from a similar function in one of the papers I read. The multiply squared ramp should probably be more of an exponential to make the slope at the very end steeper, to give more harmonics with a wider pulse, and thus a better balance of bass and treble. But honestly it's pretty good, stable, and simple to implement. Just multiplying the unsquared ramp makes it jump from sine wave to vocal sounding, but the ramp squarings really make it shine.
[EDIT] Just stuck my old "poor man's" glottal generator back in and I actually like it better than the above. It does super low "fry" type sounds infinitely better, so it covers a wider range without adjustment. And there's no DC offset to worry about. Lots of smart guys barking up that tree above though. OK, lesson learned, now I really don't care if the wave looks anything like electroglottalography or inverse filtered human voice.
Posted: 1/2/2018 11:13:15 PM
"Hi Lo" Glottal Source - Nailed!
Hoo boy, was thinking the "poor man's" glottal generator could use a scoop out to reduce the low frequency content, it hit me that I could take the NCO phase ramp, XOR it with its MSb to flip the upper half down, then flip the MSb to add 1/2. This gives a triangle wave that goes from 1/2 to 1 to 1/2 to 1 to 1/2 over the full cycle. Repeatedly multiplying this with itself gives a big-top tent-like double scoop, which I simply multiply the "poor man's" glottal result with to morph it even further:
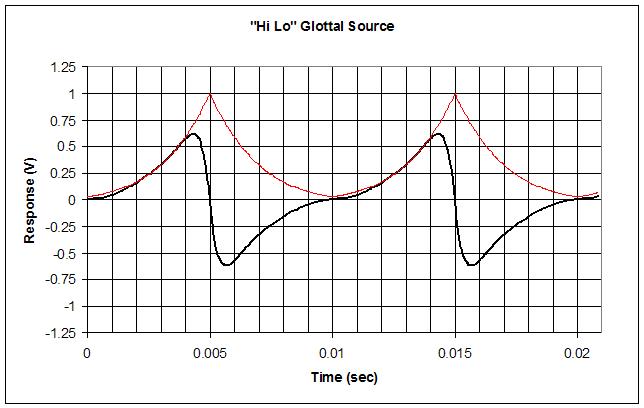
Above is what it looks like in Excel with the "poor man's" multiplication count set to 3 and the new multiplication count set to 5. The thin red trace shows the new morphing function, and the thick black trace shows the result of multiplying it with the "poor man's" morph. Note that the big-top function peaks where the "poor man's" edges are happening, so the upper harmonics aren't super-affected by the new parameter. This is why I'm calling it "Hi Lo" because the "poor man's" parameter mainly sets the highs, and this new parameter mainly cuts the lows.
The controls can be set to give a pure sine wave, a rounded square wave, a rounded sawtooth, etc. It would probably make a great generator for analog synth emulation with not too much aliasing spatter if not set too extreme. If you can do floats then the two input parameters could be made more continuous, but discrete integer multiplications give you enough control if you aren't articulating things.
It sounds pretty amazing on the prototype! It doesn't look all that "glottal" but who cares. I believe the whole point in getting the harmonics of the generator right is to balance the vocal "fry" with the upper registers (why does no one discuss this basic point in the academic literature?). My previous (today) sine * ramp^n didn't do that, but this one does, and with no DC offset problems. With this I believe I've reached the end of my glottal generator endeavors for the time being and can move on to breath / vocal dynamics. Will post a video or sound file of it in action soon.
Posted: 1/3/2018 12:24:45 AM

dewster said: "Will post a video or sound file of it in action soon."
Here is one of my never heard sound files using a simple analog theremin approach for you to compare against. I look forward after all these years to something you can demonstrate. Not knowing your end game I always wonder if you are making the very simple complicated as an engineer.
You have 135 pages on this TW thread alone cataloged in google that might seem to be a path to nowhere for new arrivals, look forward to what you will demonstrate.
My sample is one of my many discarded analog theremin voices, found in a perfectly linear pitch field. This is original but I can not play a tune. This is before you showed me how to break out the RF for even better control and manipulation of the wave shape for a beautiful theremin sound. I do thank you for that but then you went to the dark side.
You may prove my thinking wrong but I want to save the theremin from digital in the new year. Join me in a glass of Scotch whiskey or California legal weed to clear our thinking. Have you ever brought anything to market other than intellectual gibberish?
Christopher
All this vocal stuff aside, and I don't mean to sound egotistical, but by almost any measure I believe my prototype is the best Theremin in existence.
Edit: Yes and I think my baby is the cutest. Heard your sample below, to me digital sounds flat like it lacks a soul or is un-unnatural. Neither one of us can play, that can't be it. I have always thought a beautiful sounding theremin would be easier to play, at least more enjoyable which encourages play.

Posted: 1/3/2018 3:27:43 AM
Sound file (link). I obviously didn't take any care making it, probably too breathy, but I ran across this different sounding male by playing with the nose resonance, which strangely has a lot to do with the character. Anyway, the glottal generator works well through the entire vocal range with a single setting. Scooping out the pulse really tames the low end and makes the formants easier to set. Spectral view shows a certain constant harmonic fall-off in the low range, which "rounds over" to a steeper constant fall-off in the higher range. This, I believe, is a major element of good vocal synthesis.
Next up is better integration of breath noise. All vocals have breath, but the volume of it shouldn't simply track the overall volume. Pitch should have a low end below which it can't go, or turns to breath, and it should have something of an abrupt turn-on with volume. Lips are a low-pass filter, and I haven't addressed that yet either.
All this vocal stuff aside, and I don't mean to sound egotistical, but by almost any measure I believe my prototype is the best Theremin in existence.
Posted: 1/3/2018 5:30:34 AM
modified Chamberlin SV topology
What are the effects of the difference between original and "modified" versions?
Btw, I have checked, the one I'm using isn't from Chamberlin, it's an approximation to it, by J.Dattorro. It can be tuned only to < 1/4 fs, which I forgot about because the project I took it out of uses oversampling all the way and it was never a problem, but I got just reminded of that fact ;) I might have to look into that subject again. Well, I might have to actually properly learn DSP I guess, or it would at least help to know some of the problems better. So far I have been shying away from the math part. Using such things like lego blocks works to a certain degree.
Your wave sounds pretty clean, despite a lack of deliberate regards to band-limiting (?). It reminds me of that venerable speech synth singing "daisy, daisy...".
As for vocal vs. friction sounds. I wonder why classical speech synth setups of this category tend to use an own resonator path for the noise shaping. After all, there is only one vocal tract, not two that are mixed together. Just that the different sound sources are located in different places within it.
Posted: 1/3/2018 2:45:05 PM

A sample of interesting, soft, volumetric sound.
Only I do not know if this is a termenvox :-)
https://www.youtube.com/watch?v=6NOEbDjg3Wc
You must be logged in to post a reply. Please log in or register for a new account.